Adapt the composition of default process groups
DESK detects process groups using a default set of detection rules. These rules enable DESK to know which processes should be considered part of the same process group (i.e., cluster). Detection rules also determine the default names for each process group and the associated process instances (each process instance represents a node in a process group cluster).
To modify the composition of default process groups, you have to adapt the default process-group detection logic. To do this, go to Settings > Process groups > Process group detection.
On the Process group detection page, you can enable/disable specific process group detection flags. If you want more flexibility, you can define on the Process group detection page your own process group detection rules, which will override the default ones. To define a custom process group detection rule, you can either use a Java system property or an environment variable or a general process property.
- Process group detection settings and rules require a restart of your processes to affect how processes are identified and grouped.
- Process group detection settings and rules only affect the composition of process groups. If you want to change how a process group is named, you have to use the process group naming rules instead.
- It's also possible to use host groups to separate clusters into different process groups.
Process group detection flags
Tomcat, JBoss, and other applications are often deployed automatically to production. In some cases this involves the creation of new containers and directories with each deployment. Often build numbers, dates, GUIDs, and even version numbers are automatically appended to directory names (for example /opt/webapp/deployment_v1.4.45-2015-09-09/tomcat7). This presents a challenge for long-term process monitoring because it results in each new deployment being considered by DESK to be a newly discovered process. Therefore, on the Process group detection page, you should enable Ignore versions, builds, dates, and GUIDs in process directory names. By enabling this setting, any newly generated numbers, dates, or GUIDs in directory names will be ignored when determining if processes simply belong to the same cluster or if they are indeed the same logical entity. This ensures continuity of service and process-level data following the deployment of new versions.
Another option that you have in the detection flags section regards Tomcat processes. Tomcat process clusters are identified and named by default based on the CATALINA_HOME directory name. If your enable Use CATALINA_BASE to identify Tomcat cluster nodes, the CATALINA_BASE directory name will be used to identify multiple Tomcat nodes within each Tomcat cluster. If this setting is not enabled, each CATALINA_HOME+CATALINA_BASE combination will be considered a separate Tomcat cluster. In other words, Tomcat clusters can’t have multiple nodes on a single host.
Additional process group detection flags include:
- Use Docker container to distinguish multiple containers
- Automatically detect Cassandra clusters
- Use Node.js script name to distinguish processes started from the same directory in addition to application id
- Automatically detect TIBCO BusinessWorks engines
Process group detection rules based on process properties
This option enables you to define process group detection rules that are based on process properties. In this way you can create a process group by merging processes from different groups. Expand the Process group detection rules, click the Add detection rule button and select process property.
Suppose you have a process group with multiple processes. Each process concurrently performs the same function for different customers who are using your application at the same time. While each process instance has the same name, each instance runs off a unique customer-specific configuration that DESK doesn’t have information about. DESK, therefore, aggregates all related processes into a single process group to facilitate monitoring. For instances where such grouping is inadequate, you have the option of defining process-group detection rules that consider customer-specific details. Such detail can be gleaned from your unique deployment scheme. If you have a directory structure that includes a customer ID (for example, /opt/MyCustomerBasedApp/<CustomerId>/Service/MyService), and the directory structure is the same across all your hosts, you can create a customer-specific process-group detection rule that works across all process instances.
The example rule depicted below applies to processes with executable paths that contain the phrase MyCustomerBasedApp. For processes that match this requirement, the string between /MyCustomerBasedApp/ and /Service in the Executable path is extracted and used to uniquely identify each process instance.
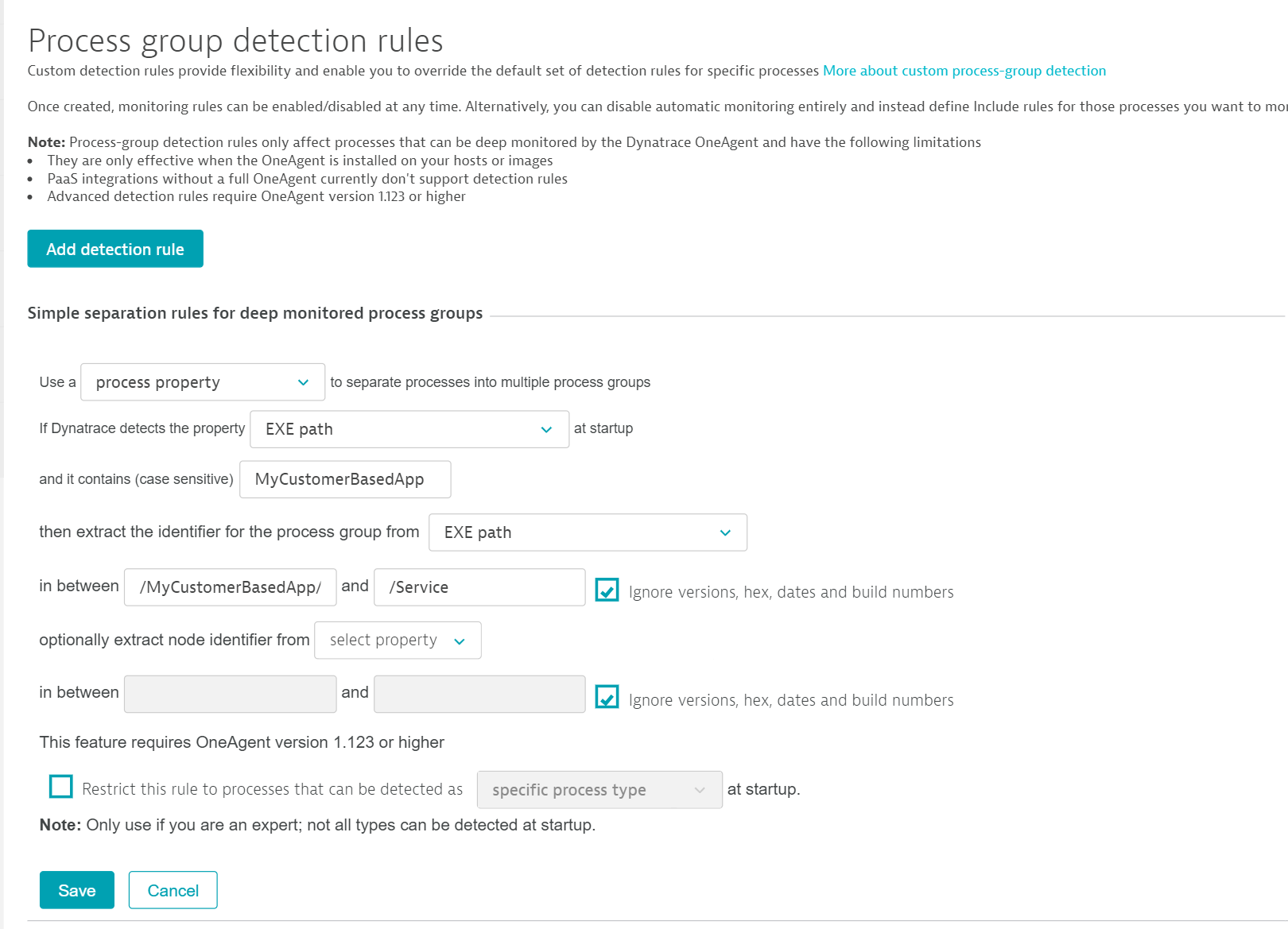
You have the option to define a second property that identifies specific cluster nodes within a process group. This is useful if your process group setup has specific names per node. If you are not sure leave this empty. The default setting is one node per host.
Process group detection rules based on Java system properties
DESK allows you to create more fine-grained groups of Java processes by using Java system property. Click the Add detection rule button and select Java system property.
This feature can only split a process group into multiple. Use this feature if DESK puts different deployments into the same process group.
The Java system property needs to be part of the java command line to be detected by OneAgent. It can either be an existing system property that your application already uses (e.g., three different jetty.home values for three different Solr clusters) or you can add a new system property. As long as the system property is available on the command line, DESK can use it.
Optionally, you can define a second property that identifies specific cluster nodes within a process group. This is useful if your process group setup has specific names per node. If you are not sure, leave this empty. The default setting is one node per host.
Process group detection rules based on environment variables
DESK process group detection settings also cover non-Java processes like NGINX, Apache HTTPserver, FPM/PHP, Node.js, IIS, and .NET. It does however work for Java processes as well. Click the Add detection rule button and select environment variable.
This feature can only split a process group into multiple parts. Use this feature if DESK puts different deployments into the same process group.
The environment variables that you select to serve as process group identifiers must exist within the scope of the detected processes. Identifiers also serve as the default name for the detected process groups.
To customize the process group of IIS, you need to define an environment variable that you can use within the scope of a rule. To set up an environment variable in IIS version 10 or later, see Environment variables.
Set up an environment variable for IIS versions earlier than 10
To set up an environment variable in IIS versions earlier than 10, follow the instructions below.
-
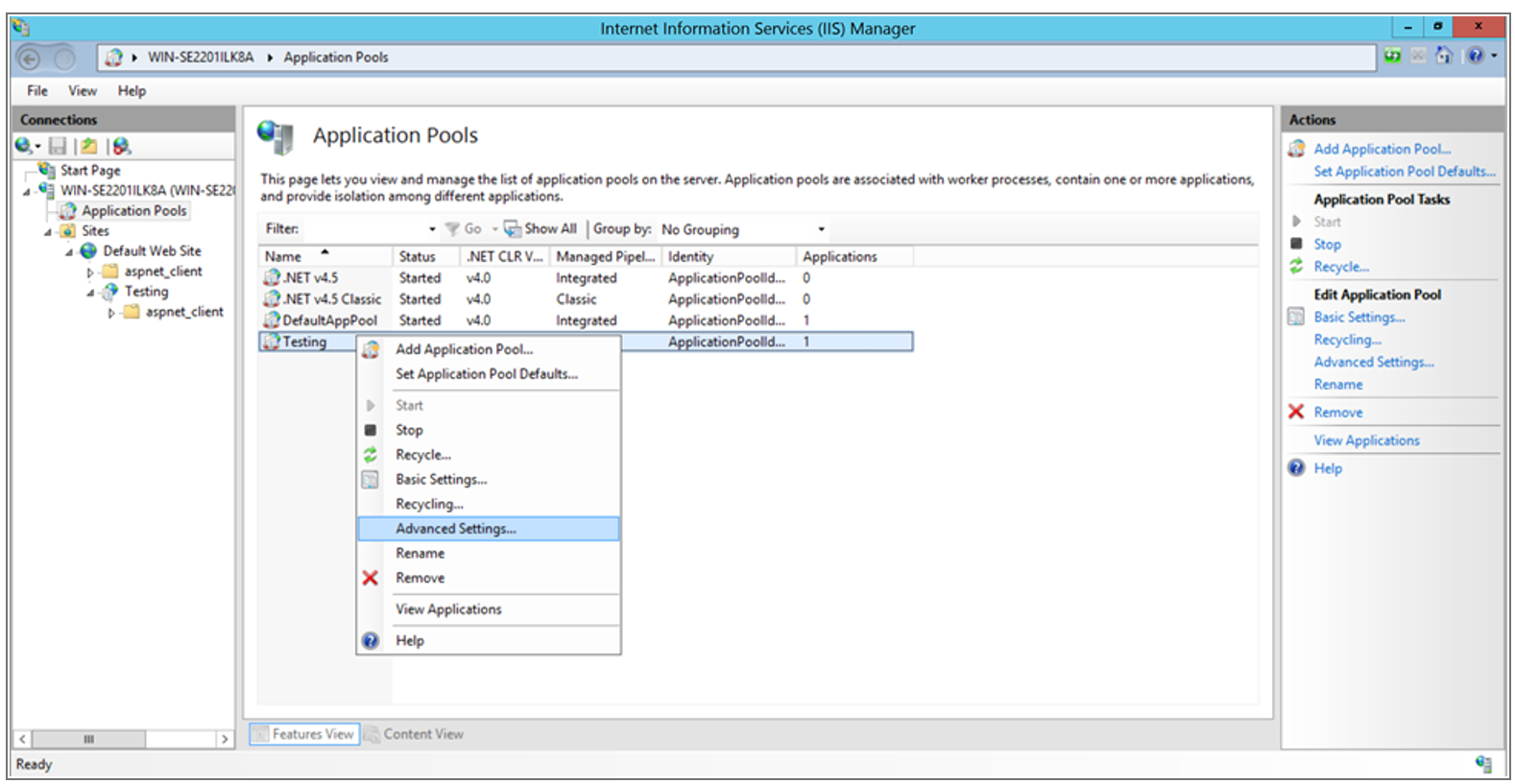
Configure the Advanced Settings for Application Pool.
-
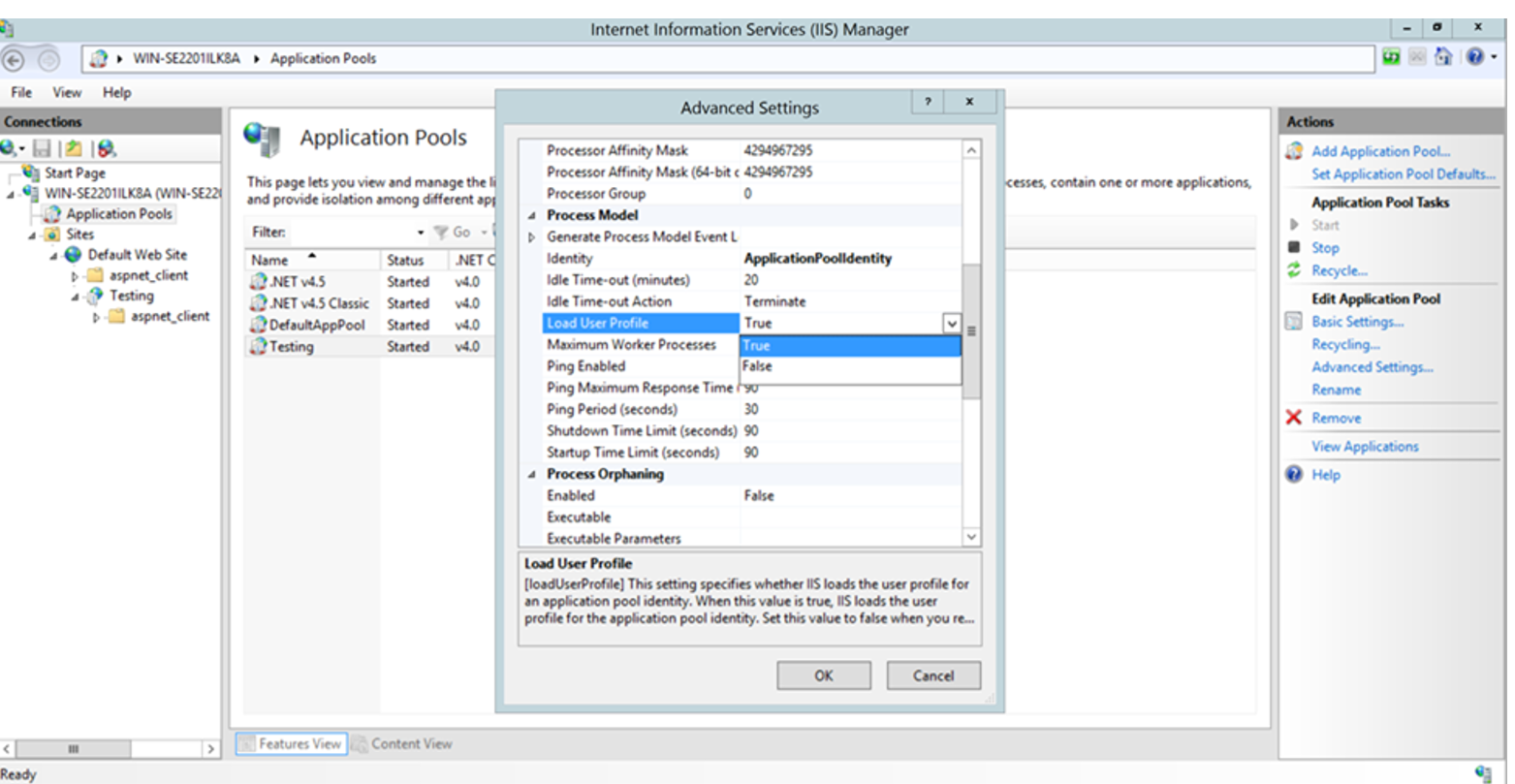
Set the Load User Profile as True.
-
Restart IIS.

-
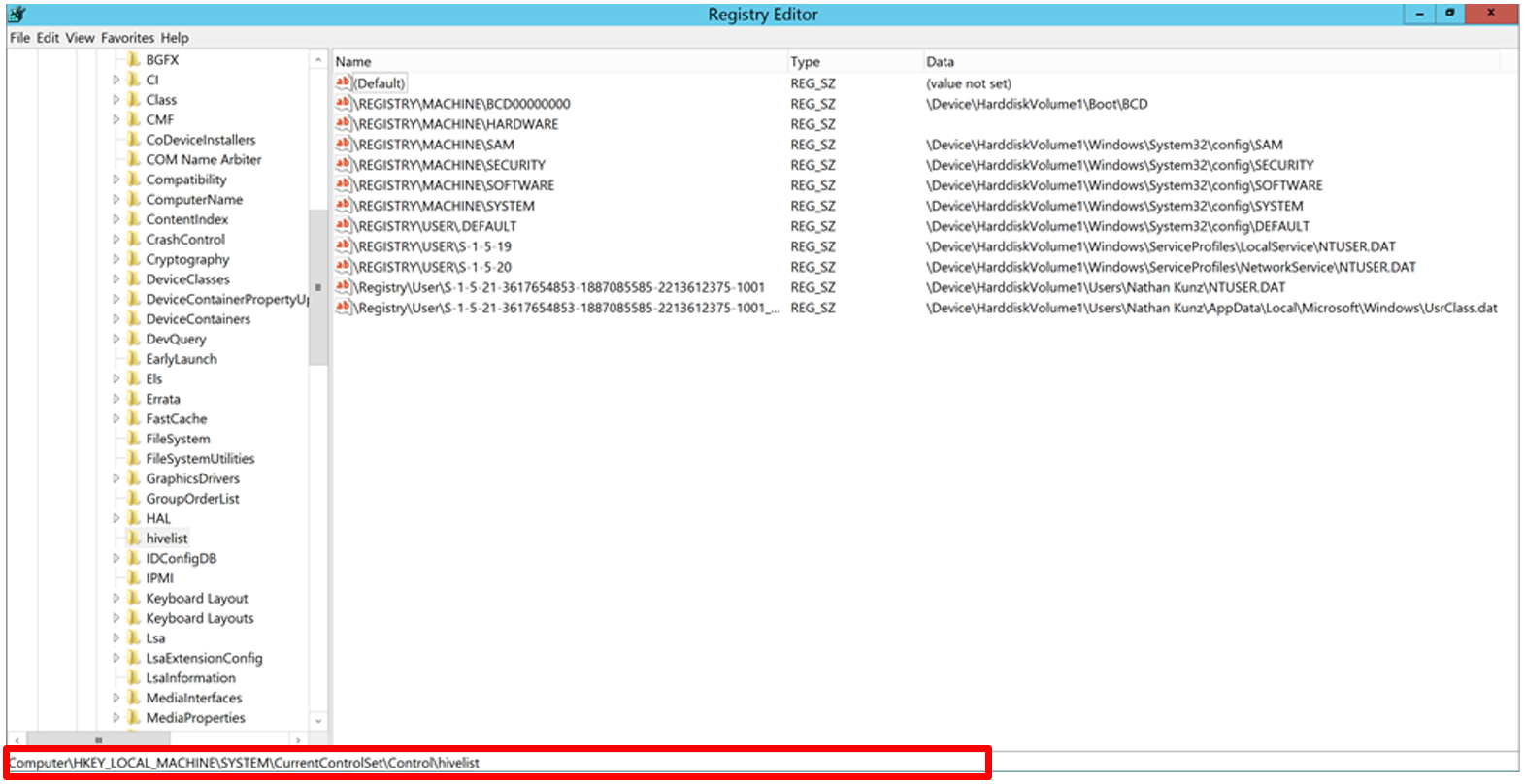
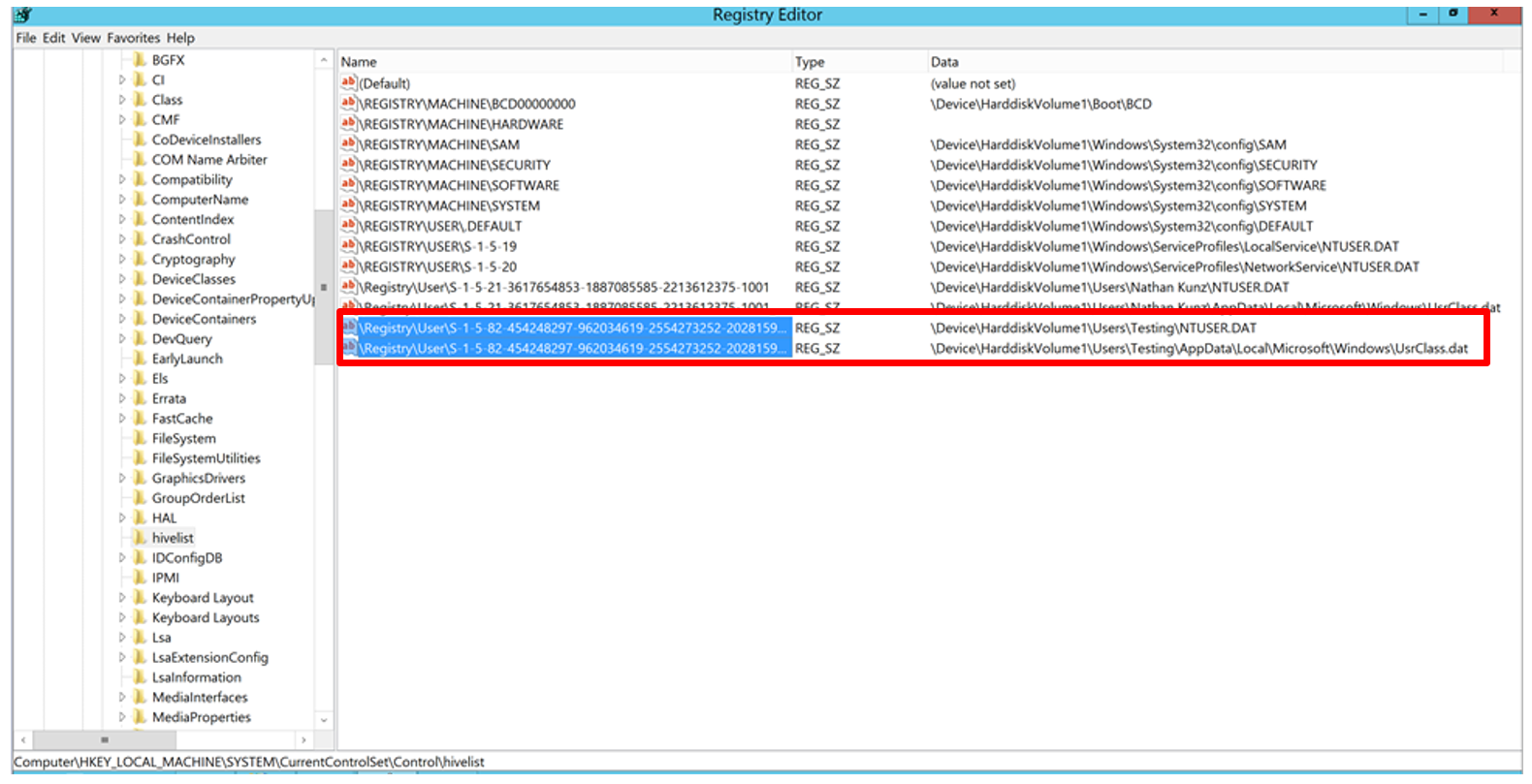
Open the Registry and navigate to
HKEY_LOCAL_MACHINE\CurrentControlSet\Control\hivelist
-
Launch the application to initialize the AppPool (or set the AppPool Start Mode to Always Running), refresh
hivelistand look for the new entries.
-
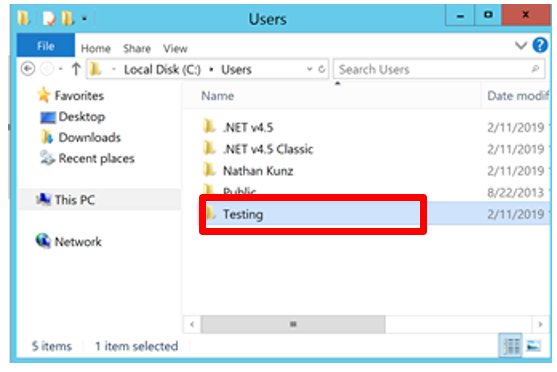
Check
C:\Usersfor the name of the user who runs the AppPool.
-
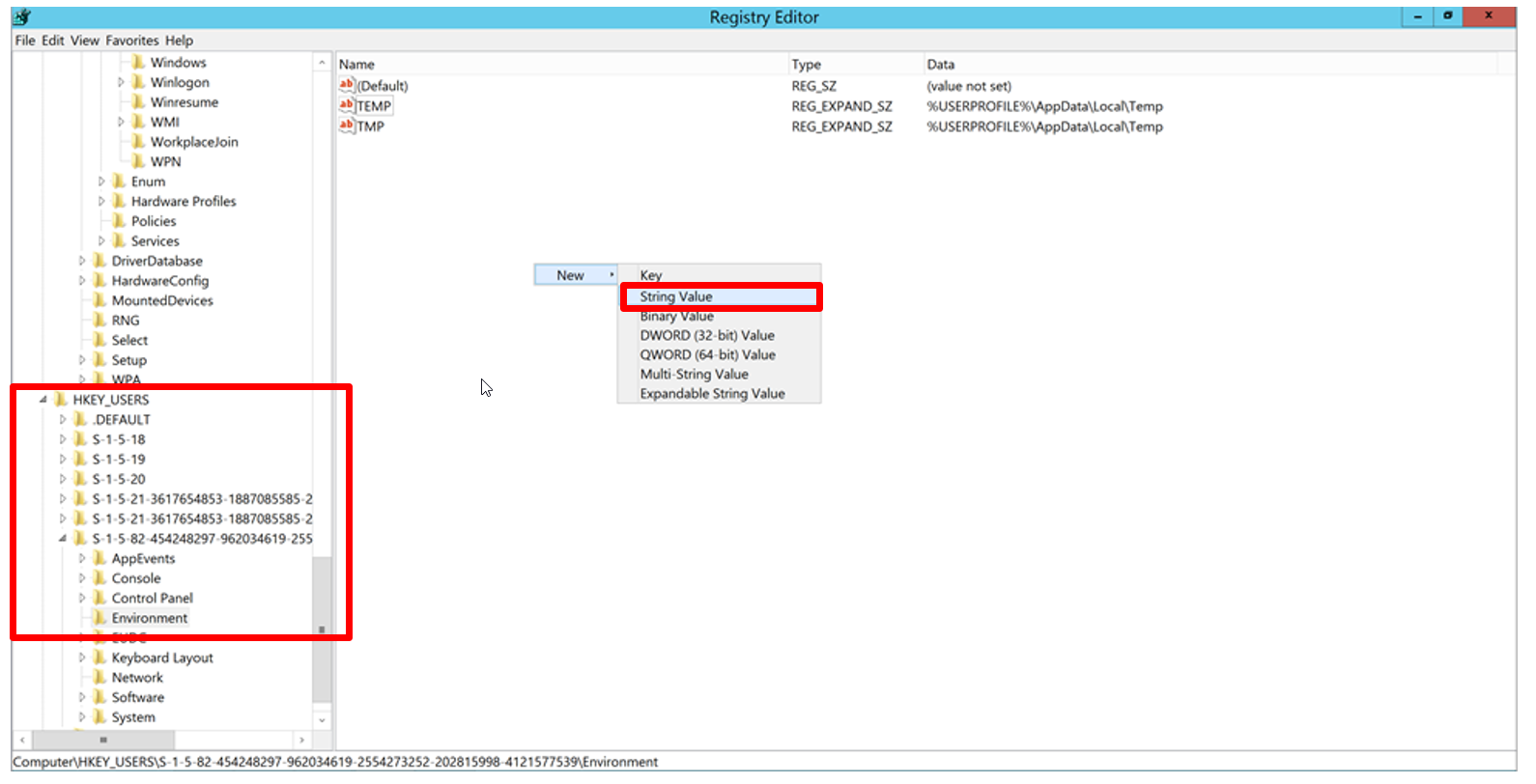
In the registry navigate to the ID of the user under
HKEY_USERSand add a String Value namedDT_CUSTOM_PROP.
-
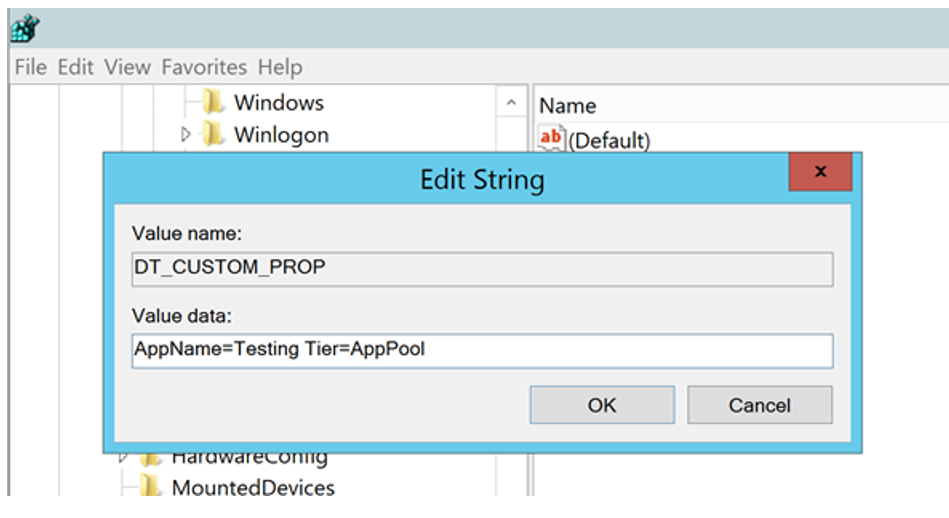
Add the value you want with spaces between the key/value pairs.
-
Restart IIS one more time and check DESK process for environmental metadata.
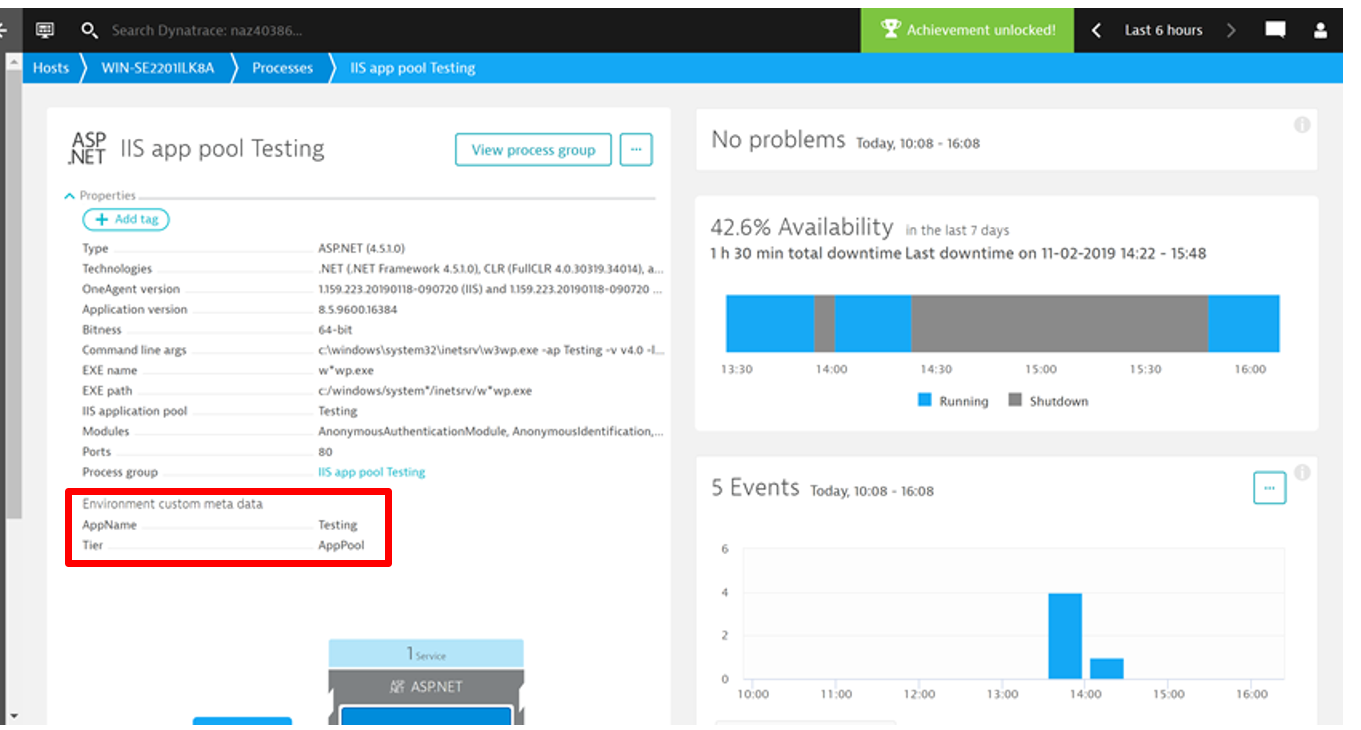
To customize process grouping for Windows services, you'll need to create a key called Environment of type REG_MULTISZ in HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\<servicename>. The value of the Environment key may contain multiple entries like in the following example:
Consider, for example, two nearly identical Apache HTTP server deployments that reside within the same deployment directory but on different hosts. By default, DESK can't distinguish between the two deployments because they don't possess any unique characteristics that can be used for identification. Now consider the following rule:

Any Apache HTTP process that includes the environment variable MY_PG_NAME within its scope will use the content of "MY_PG_NAME" as both its identifier and its default name. In this scenario, you can have DESK separately identify and name each deployment by assigning one deployment the environment variable MY_PG_NAME=desk.com-production and assigning the other deployment with MY_PG_NAME=desk.com-staging.
You can optionally type in an environmental variable to be used for identifying cluster nodes within a process group. If you are not sure, leave this empty. The default setting is one node per host.
What can I do if none of the above works?
If you have tried out the above process group detection options and none of them works, you can use the environment variable DT_CLUSTER_ID to group all processes that have the same value for this variable. All processes found in a monitoring environment that share the same cluster ID are treated as members of the same process group, separate only by the hosts they run on (for example, clusters of Apache web servers that belong together and host the same site).
Note: Be sure that you only set the DT_CLUSTER_ID variable on a process-by-process basis, not system wide! If you set this variable system-wide, all processes may be grouped into a single process group for monitoring. This is undesirable and unsupported.
To identify nodes within a process cluster that run on the same host, use the DT_NODE_ID environment variable. This tells DESK which processes should be considered separate process group instances.
Limitations
Process-group detection rules only affect processes that can be deep monitored by OneAgent and have the following limitations:
- They are only effective when OneAgent is installed on your hosts or images.
- For PaaS integrations configured for application-only monitoring, process-group detection rules are available only with OneAgent v1.149 and above.
- Advanced detection rules require DESK version 1.123 or higher.